Liberator data ingestion
This section describes how the Liberator dataset gets ingested into the data platform.
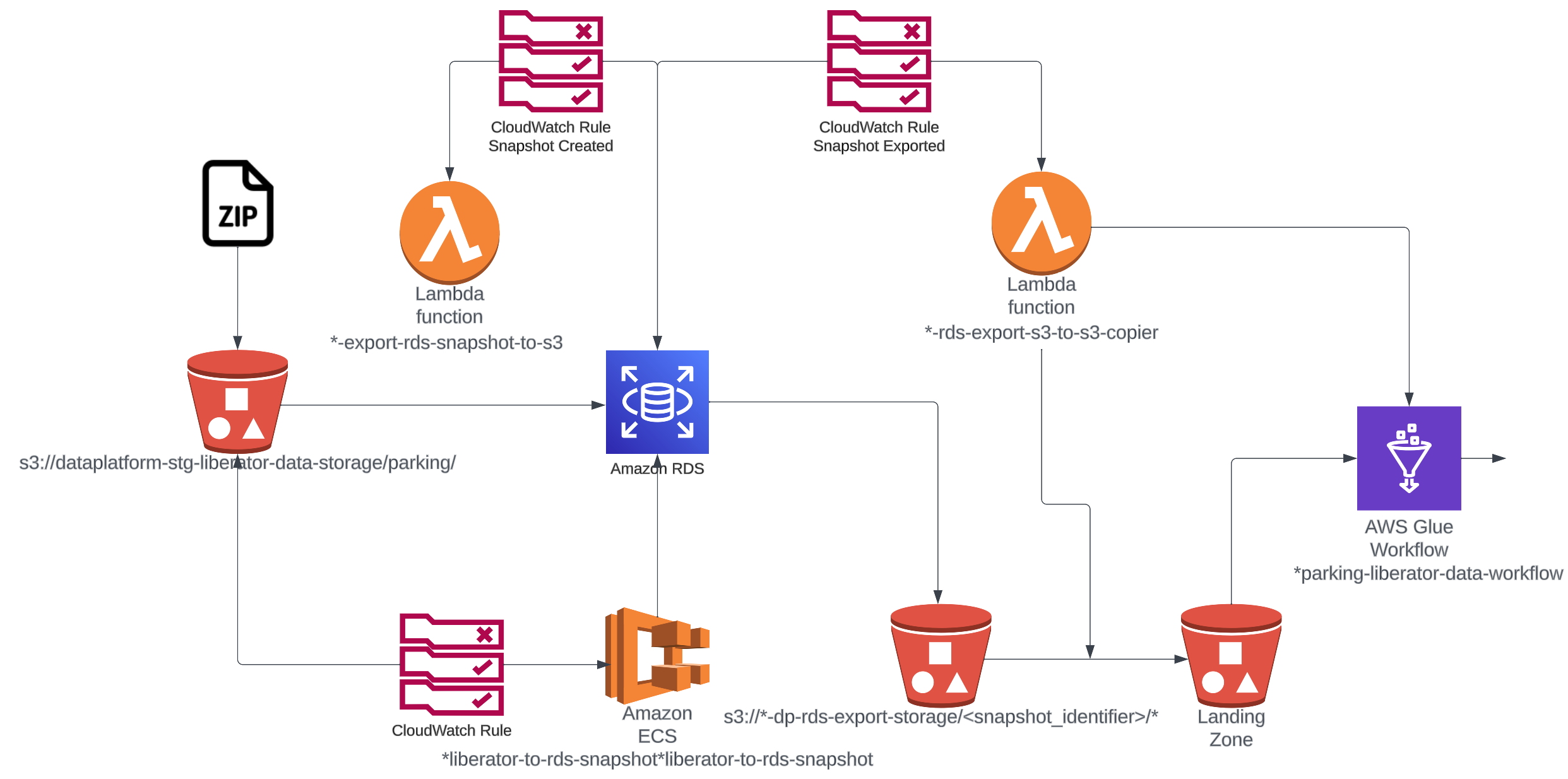
1. SQL dump is uploaded into the platform
The company who owns the dataset (Farthest Gate) uploads a zipped SQL dump of the whole database to S3 bucket in the data platform production AWS account at the path s3://dataplatform-stg-liberator-data-storage/parking/.
The file needs to be named liberator_dump_210604.zip where the date stamp at the end is the current date (format: YYMMDD).
2. RDS snapshot is created from the SQL dump
The upload of the S3 file triggers a cloudwatch event that in turn triggers the start of an ECS task (*liberator-to-rds-snapshot).
The task does the following:
- Deletes any RDS snapshots that already exist for
*liberator-to-rds-snapshotRDS instance - Unzips the file
- Drops existing database
- Creates a new database from the SQL dump
- Starts off the process to create a database snapshot from this database
3. Getting the data from the RDS snapshot into the landing zone as parquet files
A Cloudwatch Event Rule waits for the Snapshot to be created (RDS-EVENT-0042). This then invokes the lambda (*-export-rds-snapshot-to-s3) which finds the latest snapshot and starts an RDS export task that writes the snapshot to S3 (s3://*-dp-rds-export-storage/<snapshot_identifier>/*) in parquet format.
A Cloudwatch Event Rule waits for the Snapshot export to complete (RDS-EVENT-0161). When this event occurs it invokes the lambda (*-rds-export-s3-to-s3-copier) that will copy all the files into the landing zone, with the standard date partitions added to the objects keys and any extra partitions added by the RDS export task are removed.
The lambda function will then start the glue parking liberator workflow (*parking-liberator-data-workflow), which copies the data into the raw zone and runs a number of transformation jobs scheduled into the workflow.
Developer notes
When deploying to development environment the Docker image for the ECS task is not deployed automatically. You can deploy it manually by running make push-ecr from the project root.
To test the S3 file drop trigger and the entire process any zipped MySQL dump file can be used. These are readily available from various MySQL tutorials.