Using the data catalogue
How to use the data catalogue
Ingesting datasets
Datahub ingests datasets from Glue, the Glue connection is set up via a Datahub "recipe". A Datahub recipe is a yaml configuration file that instructs Datahub on where to pull data from. Please see below for a guide on how to configure the Glue recipe, this will only need to be done once when Datahub is setup
- Navigate to the
ingestiontab:
- Click
Create new source: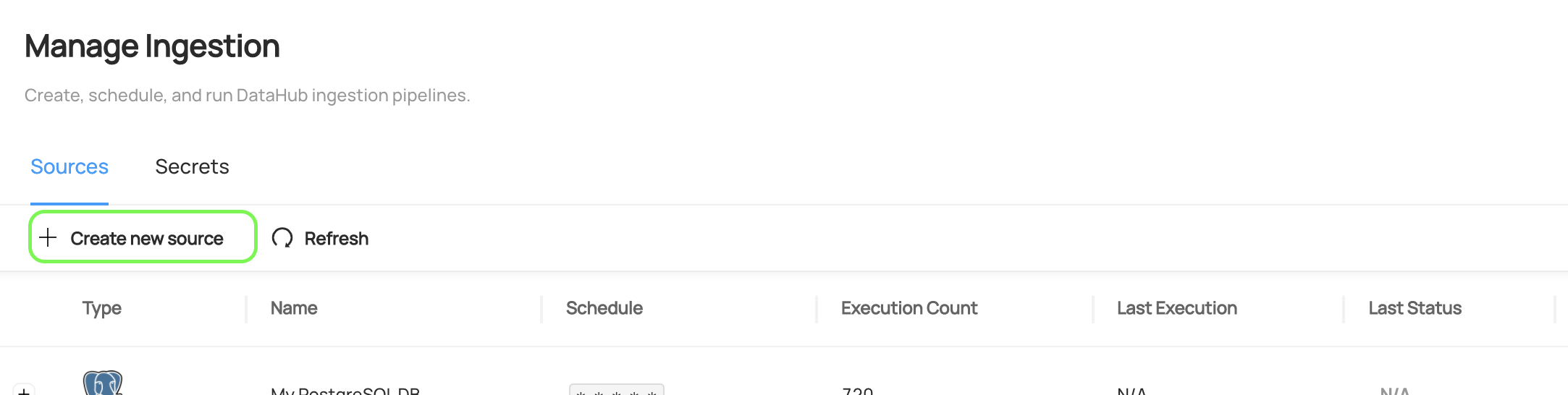
- Choose Glue
- Configure the recipe as follows (no need to change anything):
source:
type: glue
config:
aws_region: '${AWS_DEFAULT_REGION}'
aws_role: '${AWS_ROLE}'
extract_transforms: '${GLUE_EXTRACT_TRANSFORMS}'
sink:
type: datahub-rest
config:
server: '${GMS_URL}'
- Configure an execution schedule. We recommend once a day for Glue:
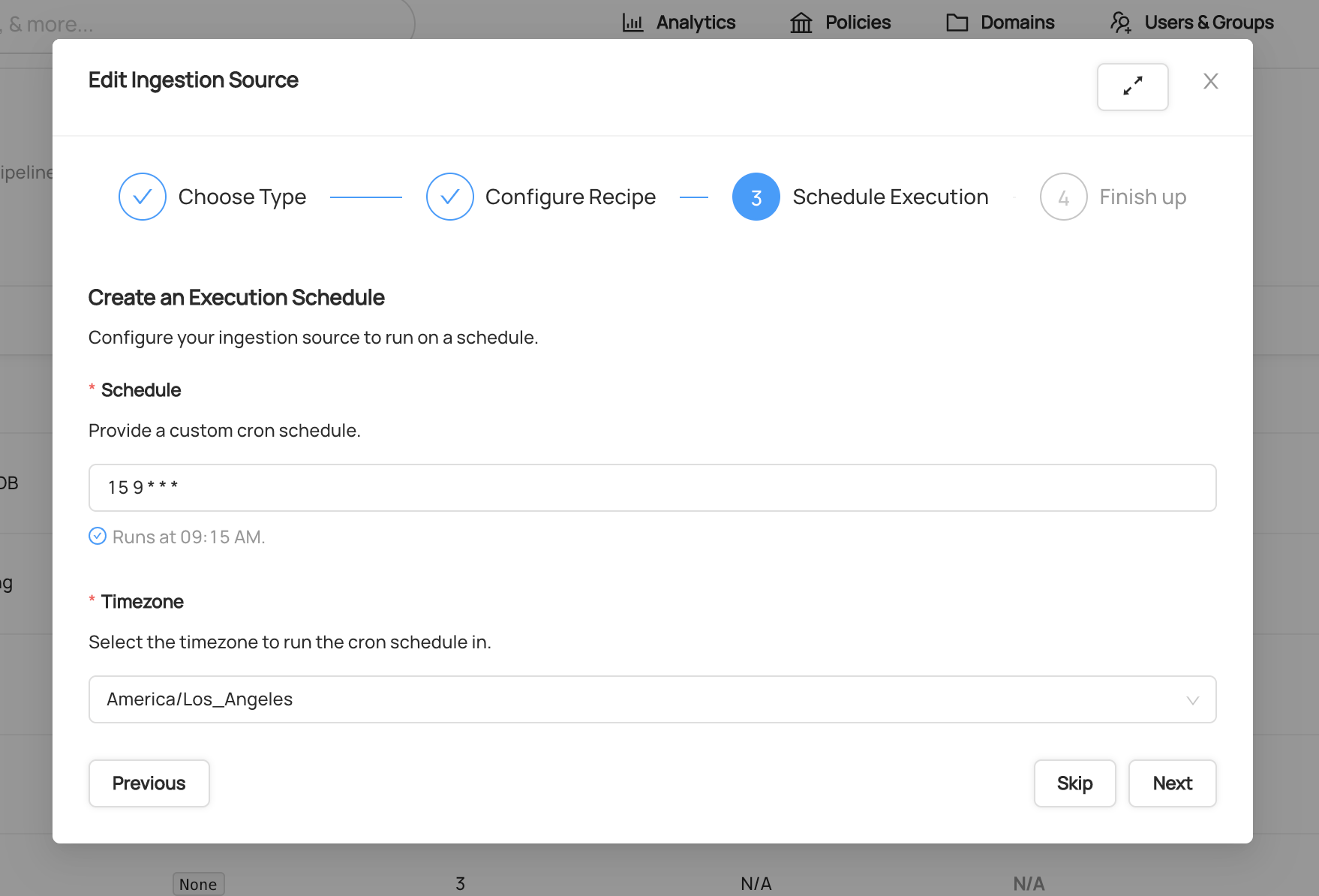 To learn more about the CRON scheduling format, check out the Wikipedia overview.
To learn more about the CRON scheduling format, check out the Wikipedia overview. - Click next and give the Ingestion Source a name of
Glue - Once you're happy with your changes, simply click
Doneto save. - Once you've created your Ingestion Source, you can run it by clicking
Execute. Shortly after, you should see theLast Statuscolumn of the ingestion source change from N/A to Running. This means that the request to execute ingestion has been successfully picked up by the DataHub ingestion executor. - If ingestion has executed successfully, you should see it's state shown in green as Succeeded.
- A variety of things can cause an ingestion run to fail, if this happens please check this guide or contact the Data Platform team
Access to datasets
- Anyone that is authenticated via Google Auth can view datasets’ metadata in Datahub
- Only people that need to edit (owners) - are created as users within Datahub
- These users will be assigned to department groups via a Datahub metadata policy that will allow edit permissions only on the datasets in their domain
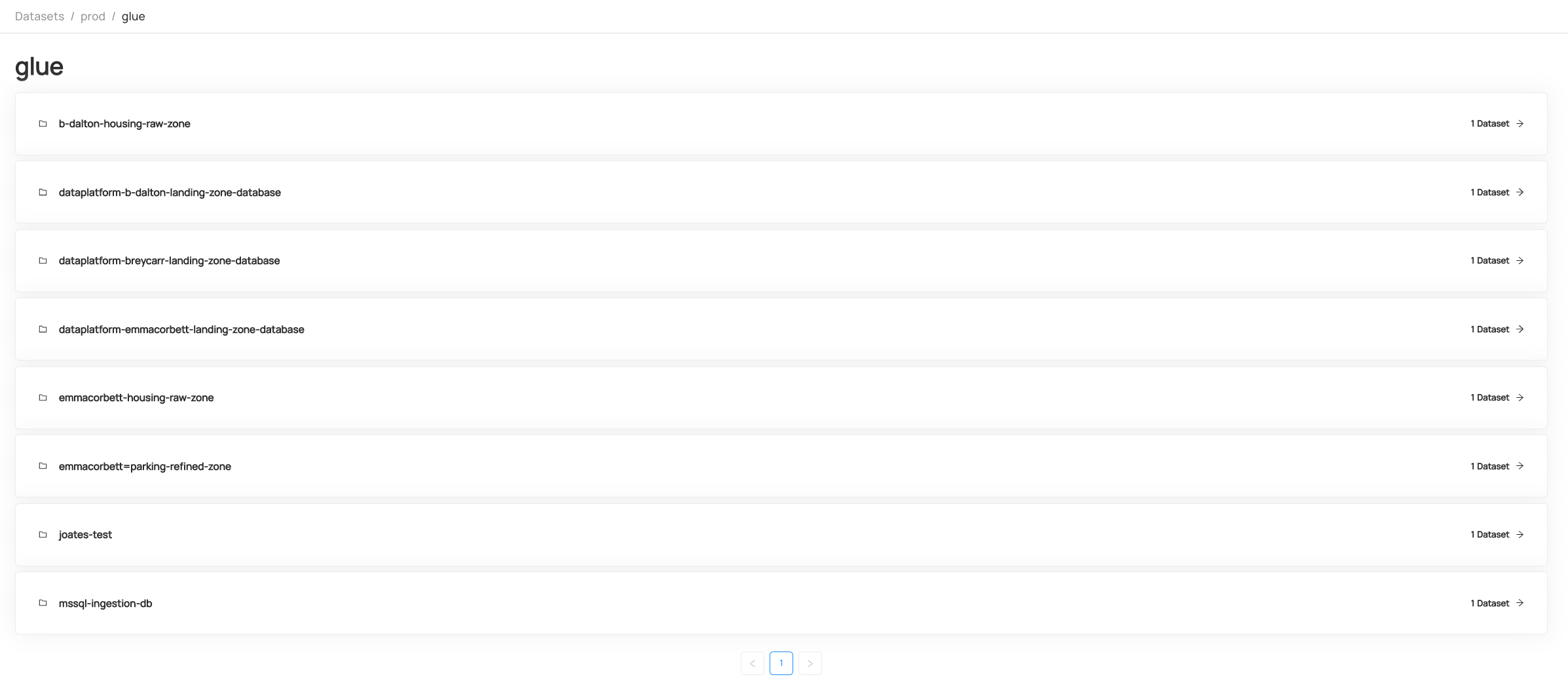
Browsing datasets
- Datasets can be found either by using the search or via the home screen
- Once a metadata ingestion recipe has been configured and executed, datasets should appear on the home screen:
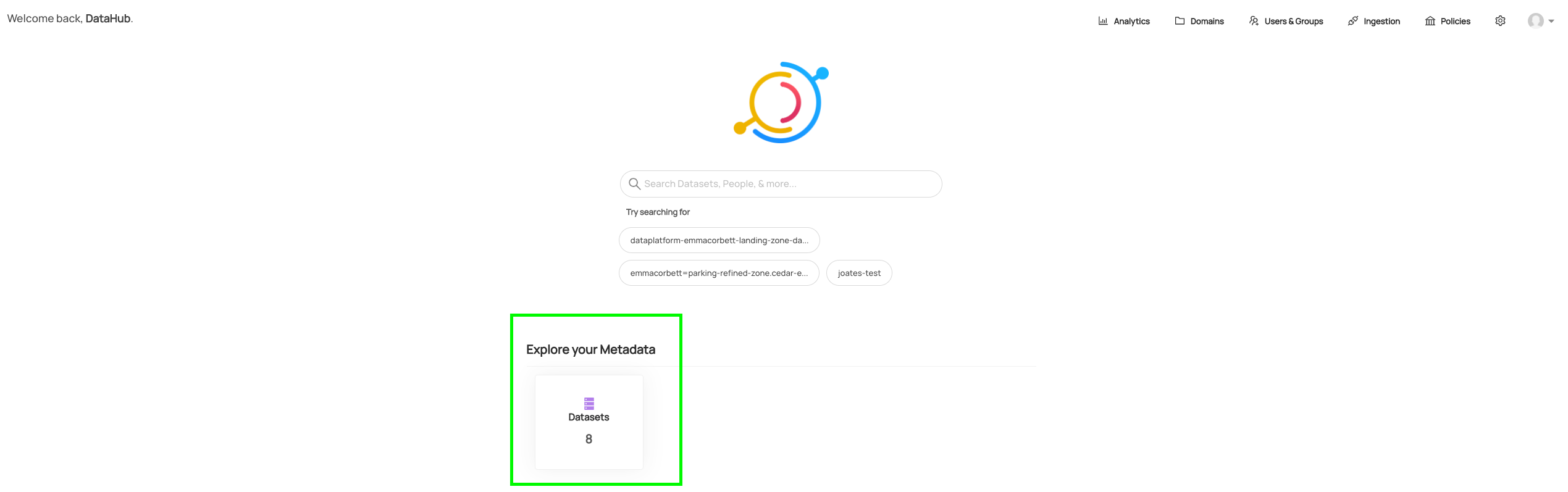
- Each dataset can then be navigated through:
Searching datasets
Please see the official Datahub Search Guide
Viewing/editing metadata for a dataset
On each dataset, there are three main tabs: Schema, Documentation, Properties
-
Schema: This shows the schema of the table including the data types of each column. More details for each Field can be found in the
Description,TagsandTermscolumns.If you are the owner of the dataset, you can edit these fields.
- To add a description to a field click on the
+ Add Descriptionbutton in theDescriptioncolumn: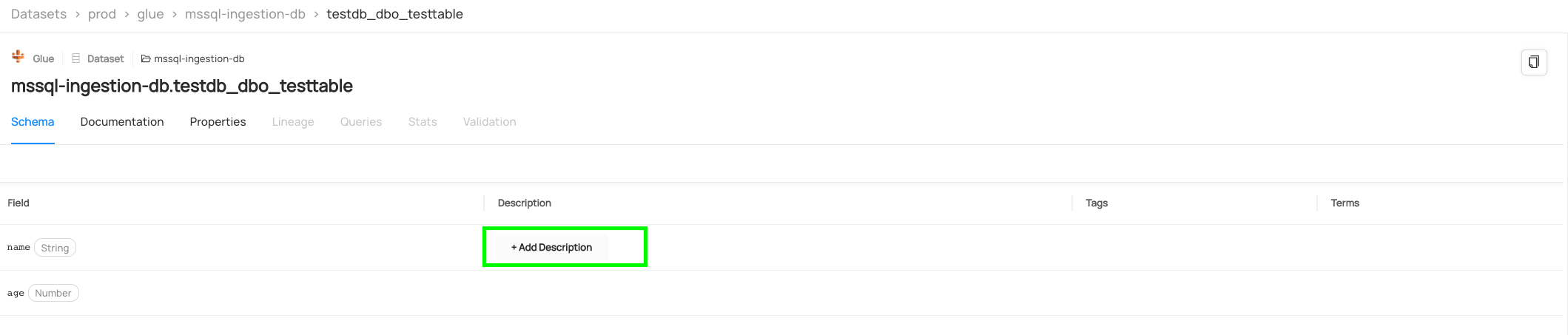
- A popup will then appear and the description can be added along with an additional text formatting:
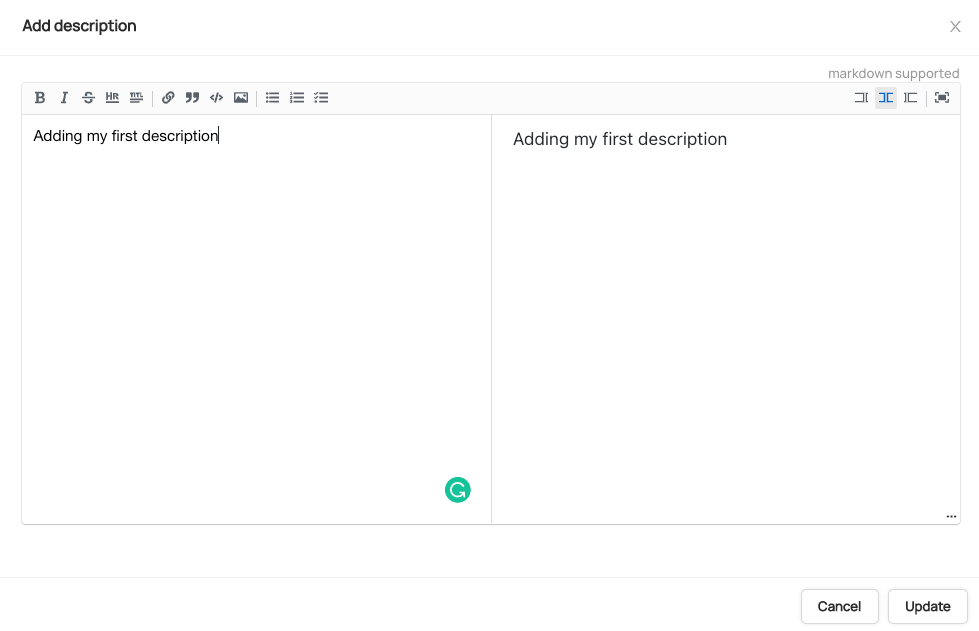
- To add a description to a field click on the
-
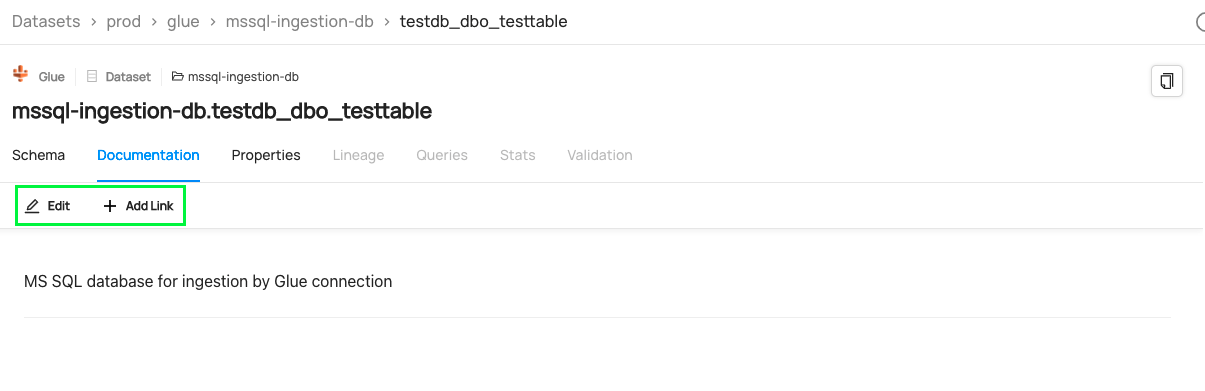
Documentation: This is a free text field where you can find general details of the dataset with supporting links. If you are the owner of the dataset, you can add documentation or edit the existing documentation.
-
Properties: This provides metadata on the dataset such as the number of records, where the data is stored, the Glue job that created it and more

Tagging
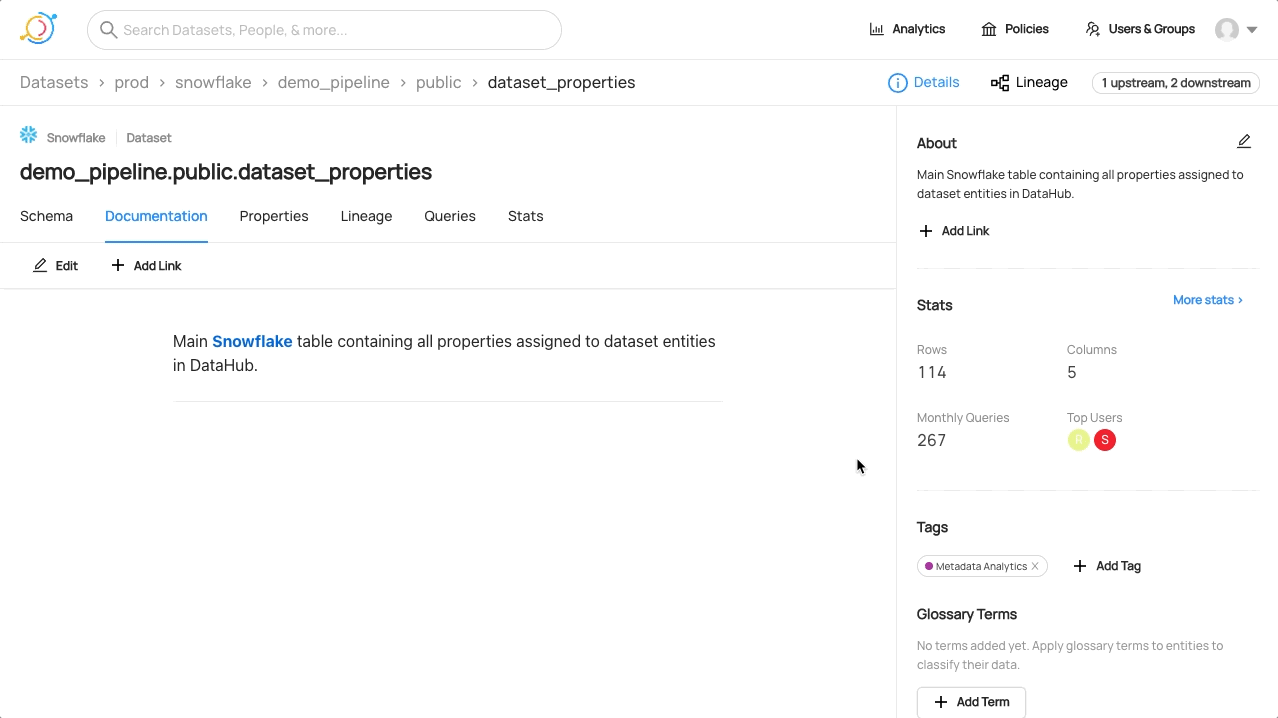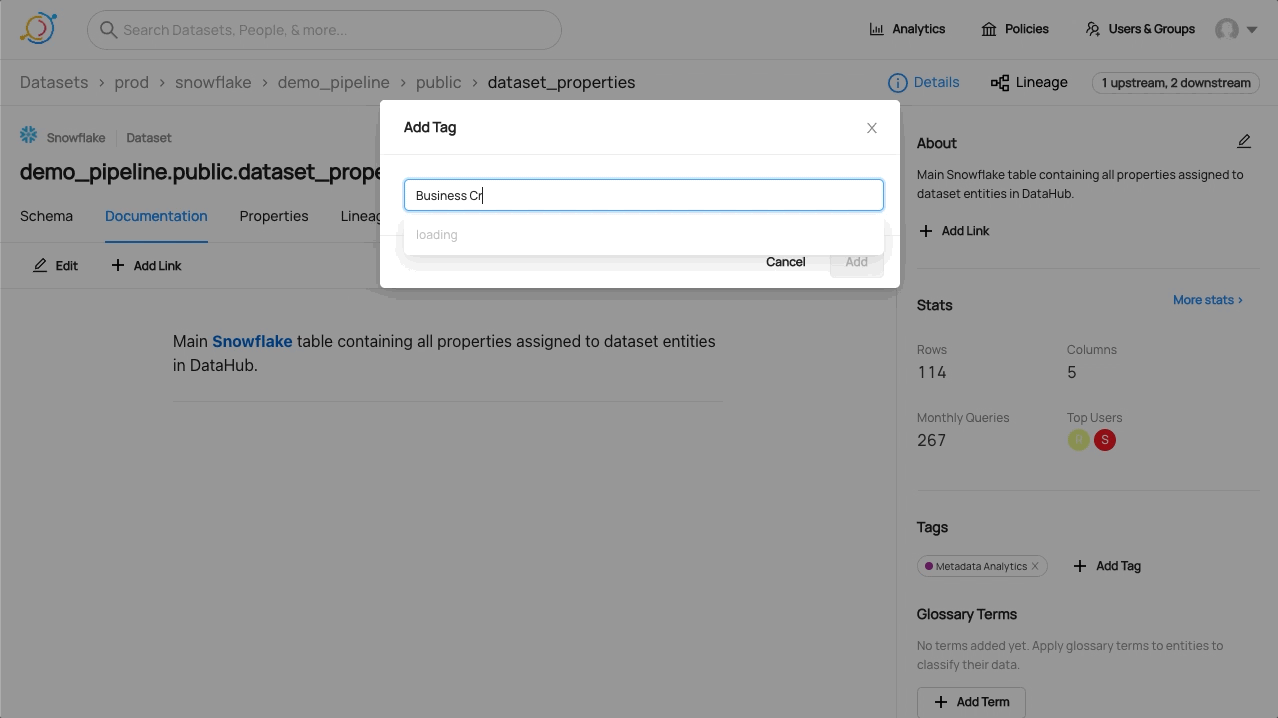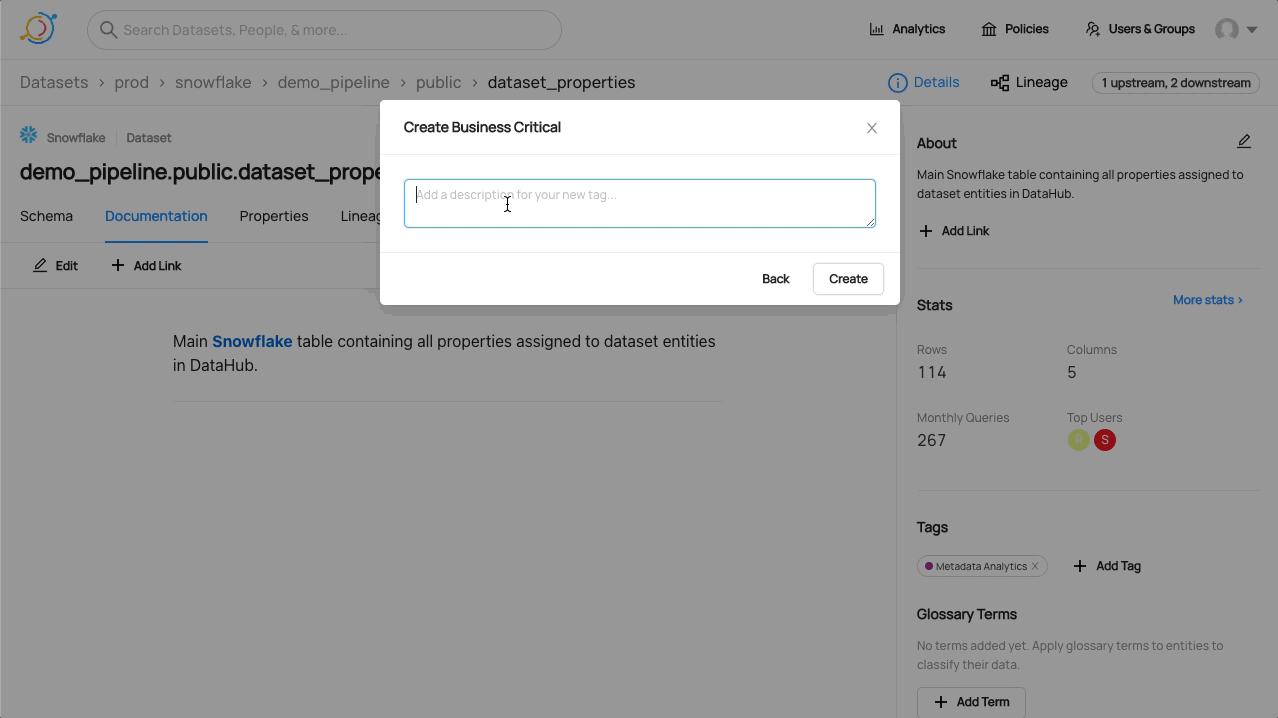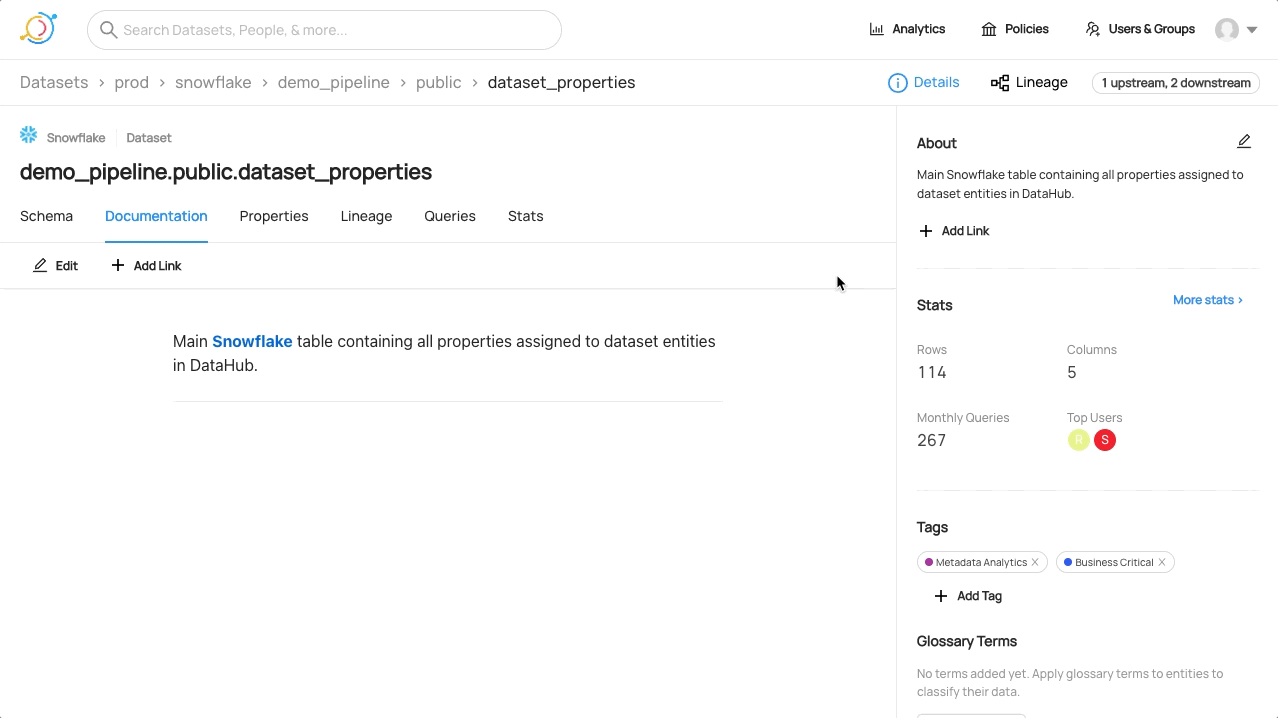 Please see the official Datahub Tags Guide for more detail
Please see the official Datahub Tags Guide for more detail
Domains
Domains can be used to organise datasets into departments, access can then be provided to users for specific domains they are interested in. Once you've created a Domain, you can use the search bar to find it. Please see the official Datahub Domains Guide which explains how to configure domains
Adding/amending owners