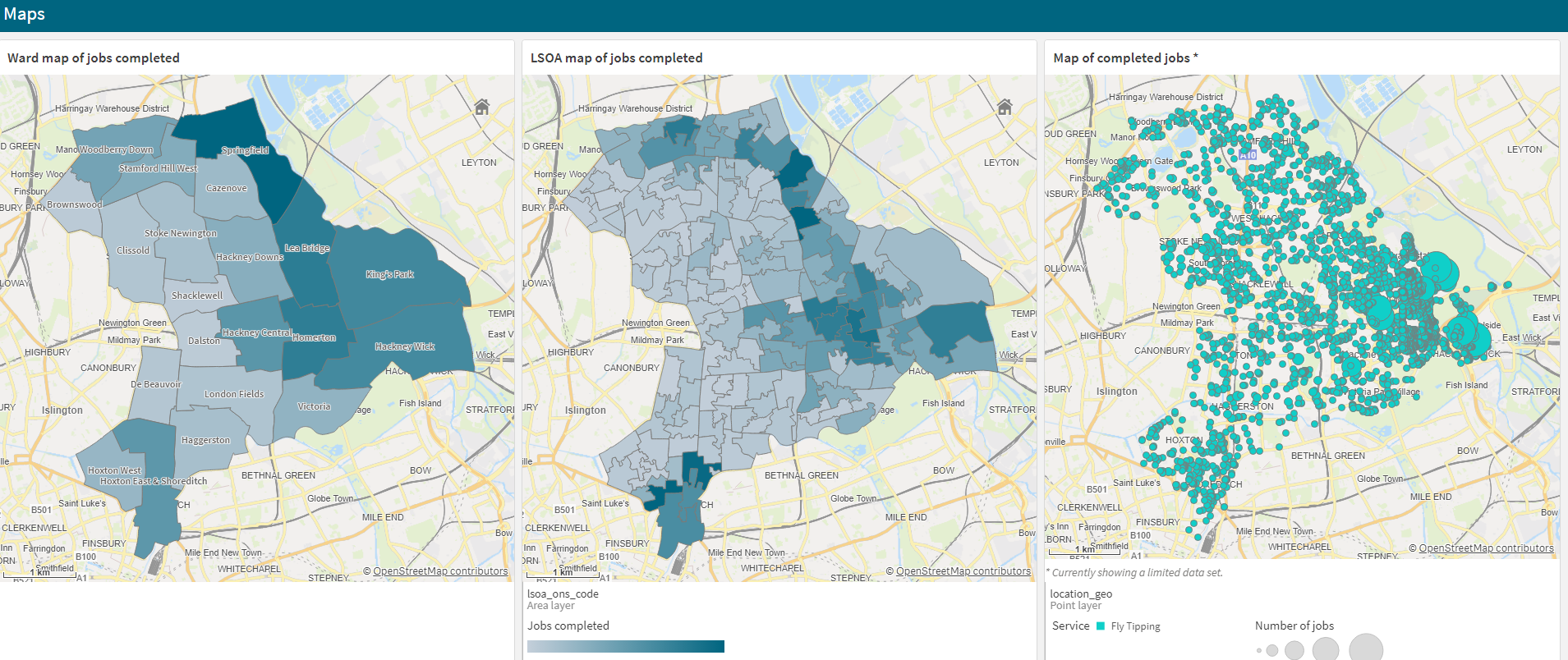
This section describes how to enrich data with geographies such as wards and LSOAs. Use this as a pre-processing step that will enable analysts to aggregate or make choropleth maps from data held in the DP. In the example below (Qlik), the 2 maps on the left were created with enriched data whereas the map on the right was created with the non enriched version.
The spatial enrichment process relies on a PySpark script that performs spatial joins between:
- input tables having some geometry information,
- and geography tables such as wards, LSOAs or estates. These are spatial layers coming from Geolive, the corporate spatial database.
The script outputs tables that have extra columns stating in which ward/LSOA/estate the record is located. This script uses Geopandas as explained in the ADR about spatial data processing in the Data Platform.
Requirements for input tables
The tables to enrich must contain geometry information that enables to geocode each record as a point (to do: support input tables with line or polygon geometries). This geometry can be represented in several ways:
- Two coords columns, either lat lon or easting/northings. The column names are not important
- One geometry column in one of these 2 formats. The name of the column is not important
- WKT (Well known text), e.g POINT (-0.020821653 51.55184938)
- WKB (Well known binary) (0106000020346C000001000000010300000001000000760000003D0AD7A36453204148E17A14387D064114AE476113532041F6285C8F167A06419A9999997D5220410AD7A37009740641C3F528DC8552204148E17A141A7306417B14AE478F522041B81E85EBE77006413D0AD7238352204148E17A14186E0641B81E8)
- (to do) a UPRN column
In cases 1 and 2, you need to know the coordinate reference system of the geometry information. Typically, it will be ‘EPSG:4326’ for lat/lon and ‘EPSG:27700’ (the code for British national grid) for easting and northing.
Where to set up an enrichment job
The spatial enrichment PySpark script is ready to use, without mofifications, in any new Terraform job module. All the geospatial enrichment job modules should be placed in the aws_glue_spatial Terraform script. Each job is specific to a department (for data access reasons) and can enrich one or more tables in one go. It will typically write into a subfolder of this department's refined zone, called 'spatially_enriched'. This location is set in the --target_location parameter, and can then get crawled if you set the crawler_details section. How you schedule the job is your choice. Note that the additional python modules (rtree, geopandas) needed for the spatial joins MUST be set as a job parameter called additional-python-modules.
This is an example of an enrichment job for Environmental Services.
module "env_services_geospatial_enrichment" {
source = "../modules/aws-glue-job"
is_live_environment = local.is_live_environment
is_production_environment = local.is_production_environment
department = module.department_environmental_services_data_source
job_name = "${local.short_identifier_prefix}env_services_geospatial_enrichment"
script_s3_object_key = aws_s3_bucket_object.spatial_enrichment.key
glue_job_worker_type = "G.1X"
helper_module_key = data.aws_s3_bucket_object.helpers.key
pydeequ_zip_key = data.aws_s3_bucket_object.pydeequ.key
spark_ui_output_storage_id = module.spark_ui_output_storage_data_source.bucket_id
schedule = "cron(30 4 ? * MON-FRI *)"
job_parameters = {
"--job-bookmark-option" = "job-bookmark-enable"
"--enable-glue-datacatalog" = "true"
"--additional-python-modules" = "rtree,geopandas"
"--geography_tables_dict_path" = "s3://${module.glue_scripts_data_source.bucket_id}/${aws_s3_bucket_object.geography_tables_dictionary.key}"
"--tables_to_enrich_dict_path" = "s3://${module.glue_scripts_data_source.bucket_id}/${aws_s3_bucket_object.env_services_spatial_enrichment_dictionary.key}"
"--target_location" = "s3://${module.refined_zone_data_source.bucket_id}/env-services/spatially-enriched/"
}
crawler_details = {
database_name = module.department_environmental_services_data_source.refined_zone_catalog_database_name
s3_target_location = "s3://${module.refined_zone_data_source.bucket_id}/env-services/spatially-enriched"
table_prefix = "spatially_enriched_"
}
}
Two dictionaries used to parameterise the job
The most important job parameters are paths to 2 dictionaries that should be committed in the repository.
Dictionary of geography tables (doesn't need to change)
The geography tables dictionary (geography_tables_dict_path parameter) tells Glue where to fetch the geography tables, what their relevant columns are, and how they should be labelled in enriched tables. These are quite standard settings and, unless you have very specific requirements for the output table, the same dictionary could be used for all enrichment jobs. The dictionary doesn't force you to use all these geographies, but it makes them available for Glue. In the other dictionary (next subsection), you'll be able to set which geographies to use for each input table to enrich. Speak to the GIS team if you need a new geography that hasn't been used before, they will amend this dictionary. Here is the dictionnary as it was when the first enrichment job was created:
[{
"ward":{"geography_title":"ward", "database_name":"unrestricted-raw-zone", "table_name":"geolive_boundaries_hackney_ward", "columns_to_append":[{"column_name":"name", "column_alias":"ward_name"},{"column_name":"census_code", "column_alias":"ward_ons_code"}]},
"lsoa":{"geography_title":"lsoa", "database_name":"unrestricted-raw-zone", "table_name":"geolive_boundaries_hackney_lsoa_2011", "columns_to_append":[{"column_name":"lsoa_name", "column_alias":"lsoa_name"},{"column_name":"code", "column_alias":"lsoa_ons_code"}]},
"msoa":{"geography_title":"msoa", "database_name":"unrestricted-raw-zone", "table_name":"geolive_boundaries_hackney_msoa_2011", "columns_to_append":[{"column_name":"msoa11nm", "column_alias":"msoa_name"},{"column_name":"msoa11cd", "column_alias":"msoa_ons_code"}]},
"recycling_estate":{"geography_title":"recycling_estate", "database_name":"unrestricted-raw-zone", "table_name":"geolive_recycling_recycling_estate_boundary", "columns_to_append":[{"column_name":"estate_name", "column_alias":"recycling_estate"}]},
"street_cleaning_area":{"geography_title":"street_cleaning_area", "database_name":"unrestricted-raw-zone", "table_name":"geolive_recycling_street_cleaning_manager_area", "columns_to_append":[{"column_name":"areaname", "column_alias":"street_cleaning_manager_area"}]},
"housing_estate":{"geography_title":"housing_estate", "database_name":"unrestricted-raw-zone", "table_name":"geolive_housing_lbh_estate", "columns_to_append":[{"column_name":"estate_name", "column_alias":"housing_estate"}]},
"housing_neighbourhood":{"geography_title":"housing_neighbourhood", "database_name":"unrestricted-raw-zone", "table_name":"geolive_housing_housing_neighbourhood", "columns_to_append":[{"column_name":"housing_neighbourhoods", "column_alias":"housing_neighbourhood"}]},
"housing_management_area":{"geography_title":"housing_management_area", "database_name":"unrestricted-raw-zone", "table_name":"geolive_housing_housing_management_area", "columns_to_append":[{"column_name":"name", "column_alias":"housing_management_area"}]},
"children_centre_area":{"geography_title":"children_centre_area", "database_name":"unrestricted-raw-zone", "table_name":"geolive_education_children_centre_area", "columns_to_append":[{"column_name":"zone_id", "column_alias":"children_centre_area"}]},
"health_care_neighbourhood":{"geography_title":"health_care_neighbourhood", "database_name":"unrestricted-raw-zone", "table_name":"geolive_health_health_care_neighbourhood", "columns_to_append":[{"column_name":"neighbourhood_area", "column_alias":"health_care_neighbourhood_code"},{"column_name":"neighbourhood_name", "column_alias":"health_care_neighbourhood_name"}]}
}]
Dictionary of tables to enrich (create a new one for each enrichment job)
The tables to enrich dictionary (tables_to_enrich_dict_path parameter) tells Glue where to fetch the input tables in the department bucket, how to manage their geometries (format, CRS, column names), and with which geographies to enrich them. Here is the beginning of the dictionnary used to enrich environmental services data.
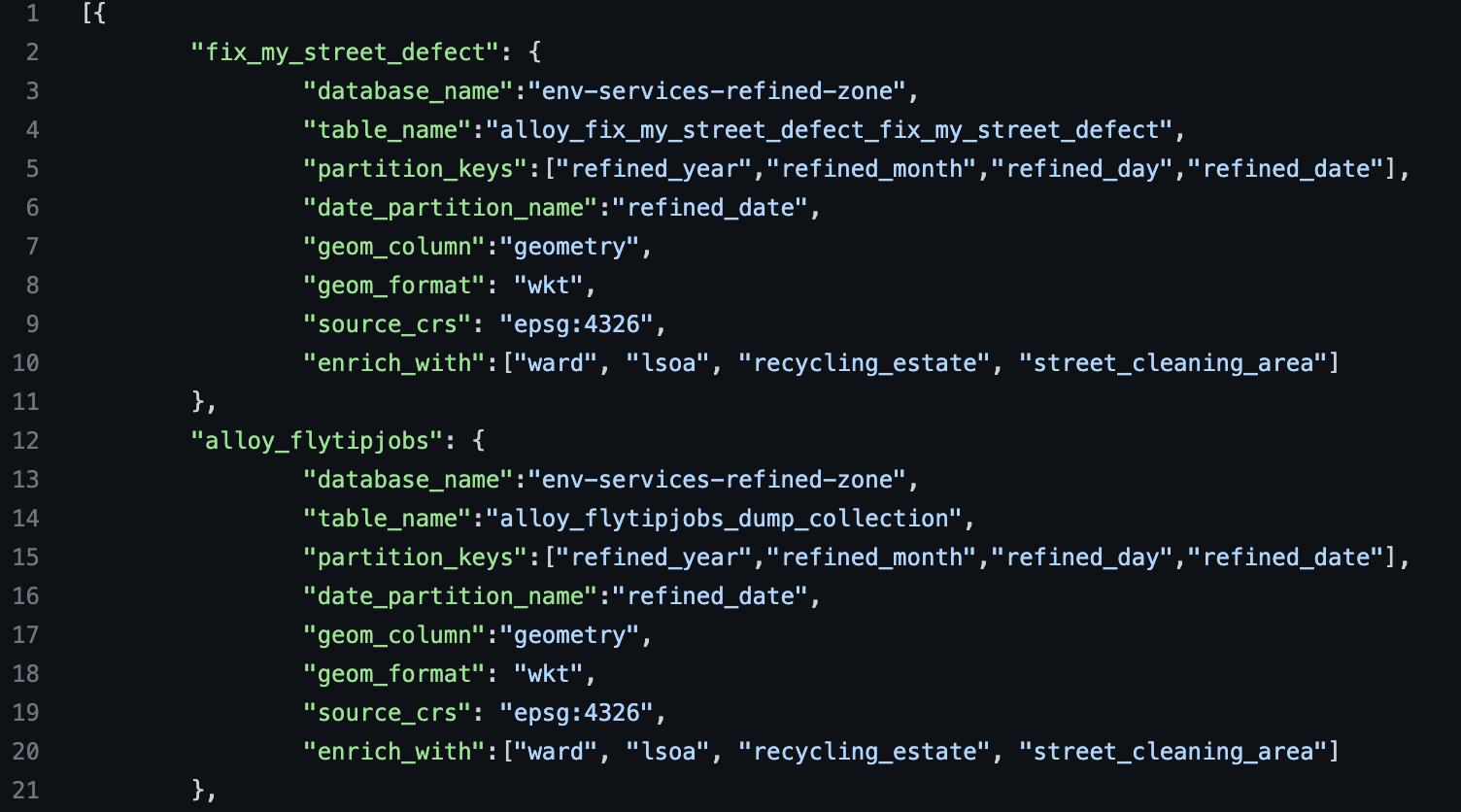
Declare your dictionary in the tf script like below so it gets copied from the repository into S3 at deployment stage.
resource "aws_s3_bucket_object" "env_services_spatial_enrichment_dictionary" {
bucket = module.glue_scripts_data_source.bucket_id
key = "scripts/env-services/spatial-enrichment-dictionary.json"
acl = "private"
source = "../../scripts/jobs/env_services/spatial-enrichment-dictionary.json"
source_hash = filemd5("../../scripts/jobs/env_services/spatial-enrichment-dictionary.json")
}