How can I use Amazon Athena to prototype a simple table-join data transformation?

1. Access Amazon Athena
🖱 In your web browser, log in to your AWS account, navigate to the AWS Management Console, and open Amazon Athena.
👉 First time Amazon Athena users should start here ► DAP⇨flow📚Amazon Athena
2. Select your [service workgroup]
🖱 Ensure you have selected your [service workgroup] from the list box next to “Workgroup”.
👉 Your Service Terms[] are defined in the welcome document stored in your [service access group] Google Drive subfolder.
3. Exploring your [service raw zone] database
🖱 Ensure you have selected your [service raw zone] from the list box under "Database" on the left side of the Athena interface.
🖱 You can then expand the lists under "► Tables" or "► Views", then expand each name further to reveal column names and data types, as follows:
-
"
▼Tables"
👉 Documented here ► 📚My service data history -
"
▼Views"
👉 Documented here ► 📚My current service data
4. Understanding the data model
👁 Identify which tables and columns you need to use for your data transformation:
-
Wherever you want a
<table>originally from your[service database]you should be able to find it's name listed under "▼Views" below your[service raw zone]database. -
For a simple simple table-join data transformation you will need:
-
The
<parent table>with a unique<parent key>. -
The
<child table>with a unique<child key>and a foreign key pointing to the<parent key>of the<parent table>.
-
5. Prepare your [transform SQL] query
🖱 You can either:
-
Start completely from scratch and building up your query in the editor as you go along;
-
Or, begin with a SQL template design, eg.
Fig. 5[SQL template], by copy-and-pasting it into the query editor.
Fig. 5 [SQL template]
-- Query will use table names from my [service database]...
SELECT
p.import_date AS original_import_date, -- added to my query
p.<parent key>,
p.<col1>,
p.<col2>,
.
.
p.<etc.>,
c.<child key>,
c.<col1>,
c.<col2>,
.
.
c.<etc.>
FROM
<parent table> p
LEFT JOIN
<child table> c
ON
c.<parent key> = p.<parent key>
ORDER BY
p.<parent key>,
c.<child key>
limit 100;
👉 You'll find considerations for SQL development discussed here ► 📚Appendix
6. Customizing a template query
When, for example, using the Fig. 5 [SQL template]:
🖱 You will need to replace the <parent table> and <child table> template placeholders with actual names listed under “▼ Views” over from the left-hand side of the interface. The Athena editor allows you to insert names directly into the code by simply clicking on the three dots ⋮ right of the name, then selecting “insert into editor”.
Fig. 6a 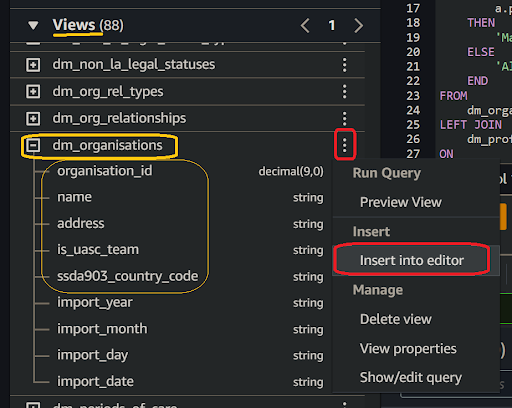
🖱 You will need to replace the <parent key> and <child key> template placeholders with corresponding key column names.
Fig. 6b 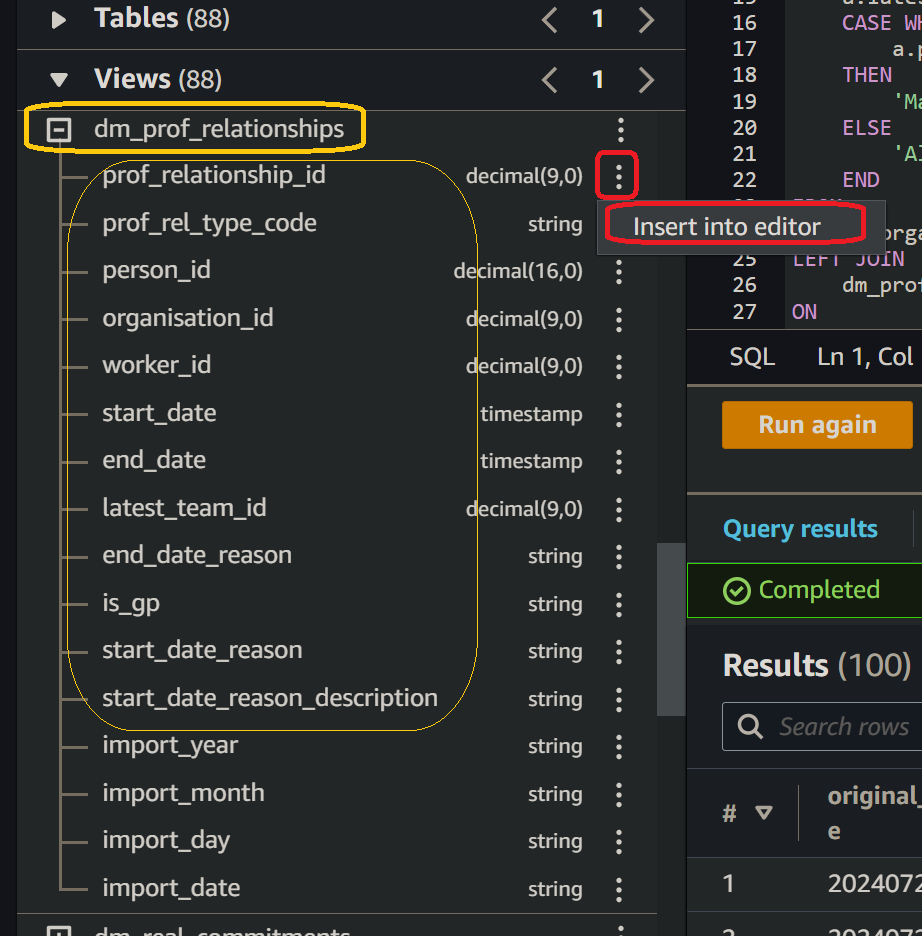
🖱 Include all the columns you need. So replace the , placeholders <col1>, <col2>, etc., with actual column names. And so on.
👉 If your column expressions require functions, you can check the Amazon Athena documentation ►here.
🖱 Edit your table names to ensure they are fully qualified, as follows:
-
Table names should be prefixed by their correct database names, eg.
[service raw zone].<table name>. -
Amazon Athena, by default, renders editor-inserted names encapsulated in
"double-quotes, eg.“[service raw zone]”.“<table name>”. You don't need to do this! But FYI, the quotes are a safeguard in case of column names containing spaces, even though we never allow that. -
Your original
[service database]database name will not be used by DAP⇨flow, so you will need to swap it out with your[service raw zone]. -
Use of fully-qualified table names means you can use tables from databases elsewhere in the Data Platform. For example, you might want to join your table from your
[service raw zone]database with a table or view from your[service refined zone]. -
You must avoid using the following column names in your transform query output because they are reserved by the DAP⇨flow implementation for writing your transform output to the S3 data lake partition folders:
import_dateimport_yearimport_monthimport_day
The
Fig. 5template example shows the columnimport_daterenamed asoriginal_import_datewhich avoids that ever being a problem.It isn't necessary to output a
original_import_datecolumn in your query but it is good practice to inform users of your transform products about which generation the data came from.Because DAP⇨flow's Airflow ingestion can trigger transforms immediately afterward, it naturally follows that, the transform output dates will be the same as the original import dates. For that reason, you might not want to use
original_import_datein your transform in production. But if the pipeline trigger logic might cause those dates to diverge in some future use case, then you should consider leaving it in.Fig. 6c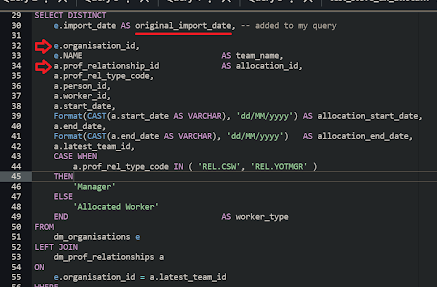
-
Here, it is recommended to order the output by
<parent key>then<child key>.💡 Transformed data is written back to S3 in blocks of records organized into separate files collated into folders representing the the S3 partition scheme. Having records written out in a coherent order makes for more efficient scanning or crawling later on.
Fig. 6d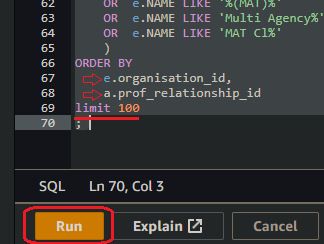
-
Adding a
limitclause at the end of your query when testing SQL queries in the Athena console normally prevents long-running queries when testing. You will routinely remove thelimitclause later when your transform goes into production.
7. Run your [transform SQL] query
🖱 After customizing the SQL code, click “Run” or “Run again” located underneath the code window on the left side in the Athena interface.
Fig. 7 
8. Review the results
👁 Amazon Athena should fetch a number of rows based on your set limit (eg. limit 100; as in the Fig. 5 [SQL template]).
-
If you included it, the first column
original_import_datawill inform us when the underlying data was ingested from your[service database]. If you do not see today’s date then you’ll immediately know that the data ingestion had failed sometime after the date shown, and you should contact the DAP Team to find out what the problem is. But so long as you have data of any given generation you can still test your transform query. -
The data should be sorted, eg., in the
<parent key>+<child key>order if that is what yourorder byclause says. -
If your query is based on a
<parent table>left-joined to the<child table>it is possible for the<child key>and its associated child columns to output NULLs in the place of values, alongside the<parent key>and parent column values. It is worth paying attention to ensure such behavior is the same way as when querying your[service database]previously.
Fig. 8 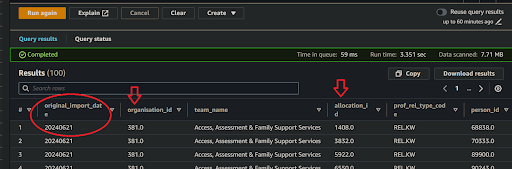
9. Save your query as [transform SQL]
🖱 Check you are in your correct [service workgroup] before clicking on the three dots ⋮ to the right of your Query tab, and clicking “Save as”.
🖮 When the dialogue pops up, enter a name for your [transform SQL] eg. [transform].sql and write a description before clicking the “Save query” button.
Fig. 9a 
Fig. 9b 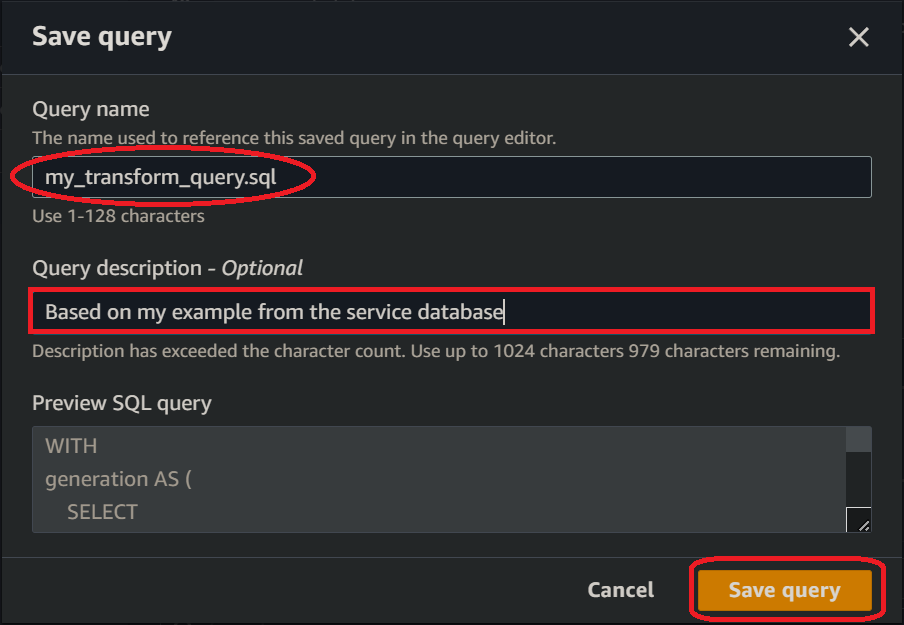
"We ♡ your feedback!"
👉 Please use this link ► DAP⇨flow UX Feedback / prototype-simple-transforms
-
Your feedback enables us to improve DAP⇨flow and our Data Analytics Platform service.
-
We encourage all our users to be generous with their time, in giving us their recollections and honest opinions about our service.
-
We especially encourage our new users to give feedback at the end of every 📚Onboarding task because the quality of the onboarding experience really matters.
☝ Please use this link to help us understand your user experience!
📚UX Criteria
- AWS Management Console user
- Amazon Athena beginner
- Hackney
[service]Data Analyst - Hackney
[service database]user
How can I use Amazon Athena to prototype a simple table-join data transformation?
Measures the behavior of Amazon Athena while users prototype simple transforms:
Given in my web browser, I have accessed Amazon Athena
~and I have selected my [service workgroup]
~and I have my [example data transformation] I want to implement using my [SQL template] involving two related tables ingested from my[service database] that I want joined to produce a combined output
~and my [example data transformation] has a <parent table> containing a unique <parent key> which is a foreign key in a <child table> which also with its own unique <child key>
~and Amazon Athena shows my [service raw zone] with my [service database] equivalent tables and columns which includes the <parent table> and <child table>
~and the optional first column output from my [SQL template] named original_import_date is based on the import_date of the <parent table>
~and my [SQL template] was designed to fetch the first <limit> rows of data in the order <parent key>+<child key>
~and I am familiar with the concepts and basic requirements of writing an Amazon Athena SQL query
When I copy-and-paste my [SQL template] into the query editor
~and I replace the <parent table> and <child table> placeholders with corresponding table names from my [example data transformation]
~and replace the <parent key> and <child key> placeholders with corresponding key column names from my [example data transformation]
~and include <col1>, <col2>,..<etc.> using column names from my [example data transformation] together with optional [SQL template] columns that I want fetched
~and I click “Run” underneath the code window on the left-hand side
Then Amazon Athena should fetch the first <limit> rows of data sorted in <parent key>+<child key> order
~and the output should comprise the columns I selected
~and an optional column original_import_date would show when the data was ingested from my [service database]
~and I can save my SQL as a working and fully functional transform query with my name [transform].sql and description in my [service workgroup].
Scale of 7 to 14 ~and flow features.
📚Appendix
Considerations when adopting Amazon Athena for your future SQL development
💡Migrating to a new technology or platform offers an ideal opportunity to raise coding standards and shed common old habits of the past.
-
You have complete freedom over the SQL code formatting however we recommend always putting each element, table or column, on its own line. This helps debugging and readability. You should endeavour to be consistent in your style and agree a particular style among your service colleagues. In our examples, we will use 4-space tabulation and use "hard left" nesting, which you are welcome to adopt.
-
Nesting has no syntactic significance to SQL interpreters so its only impact is aesthetic alone. JOIN-clauses join everything previously to the table following, and not just the previous table, so nesting them does change order of execution. Execution order can only be affected by the use of bracketed sub-queries. The hard-left nesting style, on the other hand, is designed to help the reader be conscious of the execution order above all else.
-
Avoid using lazy cartesian table products without JOIN-clauses in between the tables (or subqueries or CTEs). Likewise avoid using WHERE-clauses to perform cartesian filters and use JOIN-clauses instead. Conversely, Athena does not mind non-cartesian filters within JOIN-clauses and is even recommended where partition-columns are involved because it reduces the quantity of data scanned before any subsequent joins are executed.
-
Always consider using CTEs in place of subqueries to help debugging and readability. Amazon Athena permits VALUES table constructors in CTEs allowing replacement of very lengthy WHERE-CASE filters with the more efficient JOIN-CTE filters.